En Java tenemos objetos que implementan la interfaz Collection, que a su vez implementan las interfaces Set y List y por otra parte la interfaz Map, todas parecidas pero no iguales.
La interfaz
List. Esta está diseñada para trabajar con colecciones ordenadas y con valores repetidos e implementan esta interfaz ArrayList, LinkedList, Vector y StackLa interfaz
Set y SortedSet que hereda de la primera y la implementan las colecciones HashSet y TreeSet.Otra interfaz es
Map y SortedMap con las clases HashMap HashTable y TreeMap.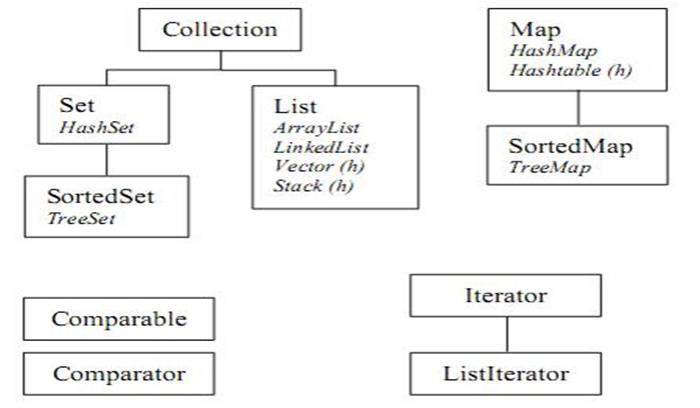
Interfaces implementadas por las colecciones

Jerarquía de clases de las listas
Veamos algunos ejemplos basándonos en el rendimiento y para ello vamos a crear una clase llamada Factura y crearemos una lista con 1.000.000 de Facturas pasándole como argumento una base imponible aleatoria y a toda la colección le calcularemos el promedio del importe final con IVA obteniendo el tiempo empleado en ms. El cálculo del promedio lo haremos con dos expresiones lambda, una con una iteración en línea y otra en paralelo, de modo que también veremos si una colección es mejor para aprovechar las características de varios procesadores o no.
public class Factura {
public Factura(double bi){
baseImponible=bi;
}
String numFactura;
double baseImponible;
double iva=.21;
public double getBaseImponible() {
return baseImponible;
}
public void setBaseImponible(double baseImponible) {
this.baseImponible = baseImponible;
}
public double getIva() {
return iva;
}
public void setIva(double iva) {
this.iva = iva;
}
public String getNumFactura() {
return numFactura;
}
public void setNumFactura(String numFactura) {
this.numFactura = numFactura;
}
public double getImporte() {
return baseImponible * (1+iva);
}
@Override
public String toString() {
return "Factura{" + "numFactura=" + numFactura + ", importe=" + getImporte() + '}';
}
}
static void addFacturas(){
List facturas=new Stack();
for (int i = 0; i f.getImporte()).average();
long endTime = System.currentTimeMillis() - startTime;
System.out.printf("Tiempo: %s ms\n" , endTime);
System.out.printf("Promedio: %f\n" , promedio.getAsDouble());
long startTime1 = System.currentTimeMillis();
OptionalDouble promedio1= facturas.parallelStream().mapToDouble(f->f.getImporte()).average();
long endTime1 = System.currentTimeMillis() - startTime1;
System.out.printf("Tiempo paralelo: %s ms\n" , endTime1);
System.out.printf("Promedio: %f\n" , promedio1.getAsDouble());
}
| Colección | Tiempo ms llenado | Tiempo ms | Tiempo paralelo |
| ArrayList | 3266 ms | 88 ms | 48 |
| LinkedList | 6410 ms | 134 ms | 5830 ms |
| Vector | 4444 ms | 92 ms | 52 ms |
| Stack | 4594 ms | 84 ms | 53 ms |
| HashSet | 9683 ms | 789 ms | 369 ms |
| TreeSet | 18861 ms | 637 ms | 636 ms |
¿Que ha pasado? ¿por qué tenemos valores de carga y valores de cálculo distintos? si son listas! Veamos los objetos que implementan la interfaz List.
El ArrayList es una lista de objetos basada en indices de acceso aleatorio donde el primero de los objetos tiene índice 0, permitiendo el ordenamiento a criterio del programador y elementos duplicados. Si nos fijamos en la tabla, se trata del objeto más eficiente en cuanto a carga de objetos y proceso de cálculo. (En el ejemplo claro, el post pretende mostrar que depende del tipo de lista, podemos obtener una mayor eficiencia).
Un ArrayList podríamos usarlo cuando necesitamos acceder frecuentemente a objetos gracias a su acceso aleatorio y acceso multihilo y no deberíamos usarlo cuando añadimos o eliminamos objetos de la lista con frecuencia. Debería ser la colección más usada.
LinkedList es una lista vinculada a otra con acceso secuencial, por tanto no es tan eficiente como los arrays. En el ejemplo, podemos observar que la carga es más tediosa y el cálculo mediante stream paralelo, se vuelve casi intratable, es decir con este objeto si intentamos realizar un stream aprovechando las capacidades multiprocesador, el resultado es totalmente opuesto al esperado. Podemos usar este tipo de lista cuando añadimos o eliminamos objetos con frecuencia.
Vector. Este tal y como lo hemos instanciado, con el constructor sin argumentos, se crea inicialmente con una longitud de 10 que una vez rebasado, se duplica sucesivamente por lo que en 18 pasos, la capacidad del Vector soporta el millón de facturas, de modo que al cargar los objetos, se produce un ligero retardo con respecto a un ArrayList que no hace ningún redimensionamiento, además sus métodos son sincronizados y solo permite un hilo de acceso a los datos, por tanto, su rendimiento es menor que el de un ArrayList.
Stack. Este objeto es una pila LIFO, Last In, First Out, último en entrar, primero en salir, por tanto solo debe usar para este tipo de funcionalidad.
Ahora analicemos los objetos que implementan la interfaz Set, la cual usamos para listas con objetos ordenados o no, sin objetos repetidos usando los métodos equals() y hashcode() para determinar la igualdad; el hecho de no incluir elementos repetidos, se debe a los métodos señalados.
HashSet. Esta colección es un fiel reflejo de su interfaz, no permite elementos repetidos, su crecimiento se basa en una capacidad inicial de 16, doblada en la siguiente redimensión y con factor de crecimiento de 0,75 en las posteriores y no permite ordenamiento. El hecho de no permitir duplicados, atiende a la falta de rendimiento del ejemplo, ya que cada vez que se añade un registro, se debe comprobar la no duplicidad del elemento.
TreeSetEsta colección ordena los elementos cada vez que se inserta uno nuevo, de ahí el gran retardo en la inserción de datos.
Como conclusión, es fundamental que analicemos la cantidad de datos a tratar, el número de inserciones y eliminaciones, ordenamientos, posibilidad de proceso multihilo y que cálculos vamos a realizar con los datos. Una vez analizados los datos, la elección de vuestra colección es el siguiente paso y a continuación, los test de rendimiento para retroalimentar el análisis en su caso.
